Most AI benchmarks are rigged.
Not maliciously – just practically. People write elaborate prompts that basically pre-chew the answer, then congratulate the model for swallowing nicely. That’s not a benchmark. That’s babysitting.

I needed a work directory organiser.
Two columns, add row, insert row, delete row, drag to rearrange. That was the entire prompt.
No wireframe.
No design brief.
No “please make it dark themed and accessible and responsive with smooth animations.”
Just the requirements, stripped bare.
I gave that exact prompt to three AI coding tools – Qwen, DeepSeek, and z.ai – and watched what happened.
The results were instructive. Not because of what the models built, but because of what they revealed about how they think.
Why Minimal Prompts?
When you over-engineer a prompt, you’re doing the model’s job for it. You’re filling in the gaps, making the decisions, resolving the ambiguities. The model just executes your blueprint. Fine for production. Useless as a test.
A minimal prompt forces the model to make choices. And the choices it makes tell you everything.
Does it stay on spec?
Does it add things you didn’t ask for?
Does it misread what you needed and go off on its own agenda?
I work with minimal prompts by preference – not laziness. I’m 66, self-taught since last year, and I build tools for real people doing real work. I don’t have time for prompt engineering ceremonies. If an AI can’t read a plain-English spec and deliver accordingly, it’s not useful to me.
The Prompt
Verbatim, in its entirety:
I need a 2 column spreadsheet. Add row, insert row, delete row. And the biggie: re-arrange rows.
That’s it. No tech stack specified. No visual requirements. No column names. No storage instructions. Just the behaviour I needed.
The Results
z.ai – Wrong meeting, bru.
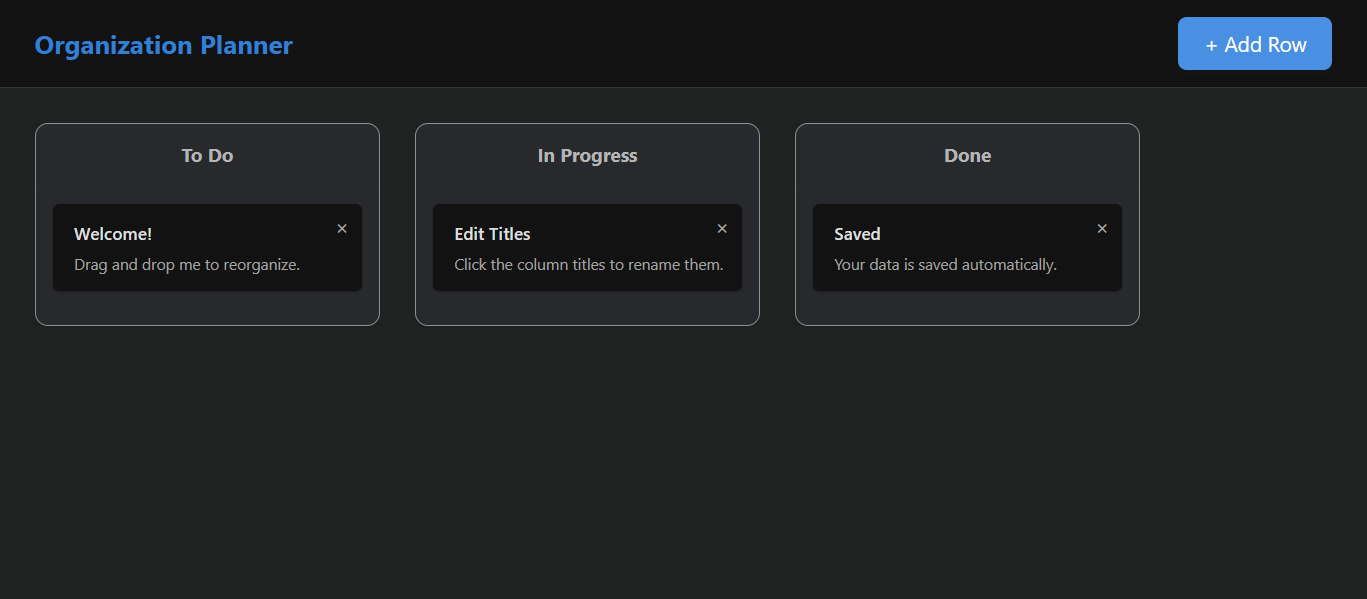 z.ai built a kanban board. A genuinely decent kanban board. Nicely styled, functional, clearly some thought went into it.
z.ai built a kanban board. A genuinely decent kanban board. Nicely styled, functional, clearly some thought went into it.
The problem: nobody asked for a kanban board. The prompt said “2 column spreadsheet.” Somewhere between reading that and generating output, z.ai decided what I actually needed was a project management view with cards and columns and drag-between-lanes behaviour. It substituted its own interpretation for the stated requirement.
This is the “I know better” failure mode. The model tried too hard, looked for the cleverer answer, and missed the obvious one. Raw capability isn’t the constraint here – the constraint is discipline.
DeepSeek – Almost, but not quite.
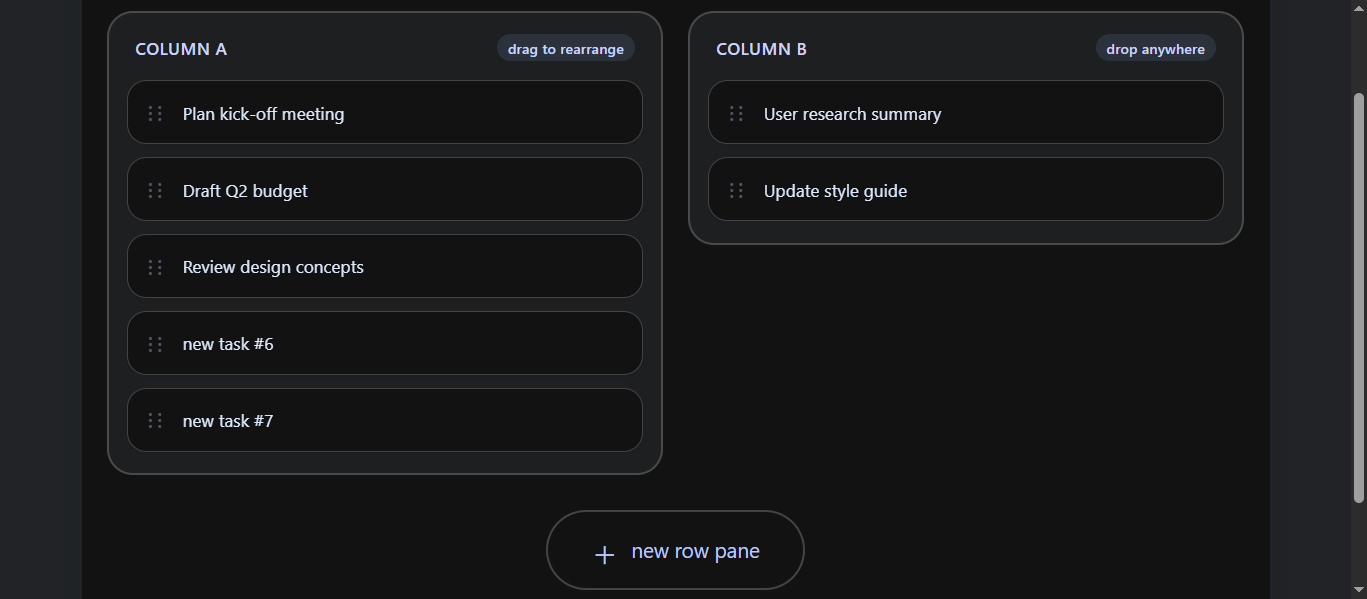 DeepSeek got the core right, then couldn’t help itself. It delivered the spec – but also added something that wasn’t asked for. One feature short of complete (insert row was either missing or ambiguous), one feature added that wasn’t in the brief.
DeepSeek got the core right, then couldn’t help itself. It delivered the spec – but also added something that wasn’t asked for. One feature short of complete (insert row was either missing or ambiguous), one feature added that wasn’t in the brief.
This is the “but what about” failure mode. The model read the spec, executed most of it, then went looking for gaps to fill. The instinct isn’t bad – in a collaborative context, it’s even useful. But in a spec-compliance test? It’s a miss.
Qwen – On target.
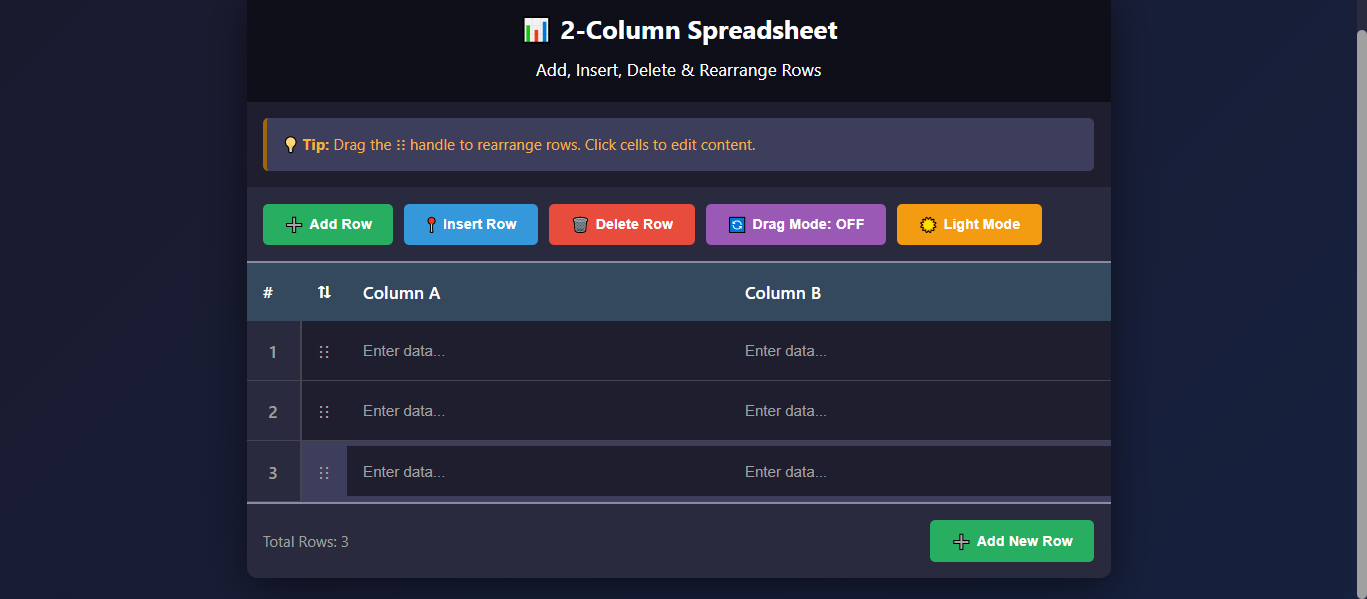 Qwen read the prompt and built exactly what was asked. Two columns. Add, insert, delete, drag-to-rearrange – all present, all working. Nothing added. Nothing missing.
Qwen read the prompt and built exactly what was asked. Two columns. Add, insert, delete, drag-to-rearrange – all present, all working. Nothing added. Nothing missing.
What makes this more interesting: Qwen has a memory feature, and it’s been exposed to my working style over time – minimal inputs, dark theme preference, no tolerance for over-engineering. Whether the memory contributed to the clean output or whether Qwen just reads specs accurately, the result was the same: it did the thing I asked, the way I’d have done it.
What This Actually Measures
Prompt accuracy and model intelligence are not the same thing. z.ai is probably the most capable model of the three in raw terms. It still failed the test.
A minimal prompt benchmark tests three things:
– Spec adherence – does the model build what was asked, not what it imagined?
– Restraint – can the model resist the urge to over-deliver?
– Interpretation – when the spec is ambiguous, does the model resolve it sensibly or go rogue?
For solo builders who work fast with lean prompts, restraint matters as much as intelligence. An AI that adds unrequested features creates rework. An AI that misreads the brief entirely creates more rework. An AI that just does the thing is worth its weight in pretzels.
The Broader Point
I’m not a developer. I started coding in May 2025 at 65 years old, building desktop tools for solo workers and freelancers under my Beachy Studio brand. My entire workflow depends on AI that listens rather than interprets.
The minimal prompt test isn’t about catching AI out. It’s about finding out which models are useful collaborators for people who work the way I work – lean, fast, plain English. If your AI requires a detailed prompt to behave, that’s a cost. Not a deal-breaker, but a cost.
Try it yourself. Pick something you actually need. Write the most stripped-back spec you can. See what comes back. The results will tell you more about your tools than any benchmark site will.
I design and build desktop tools for everyday users at beachy.co.za. Working primarily with HTML, CSS, and JavaScript, I take a leadership-driven approach to modern development — using AI to handle repetitive groundwork while I focus on structure, performance, and real-world usability.
I’m intentionally transparent about this workflow. In a landscape where many developers quietly rely on automation, I believe clarity builds trust. My role is to guide the build process, make architectural decisions, and take full responsibility for the final outcome.
For me, a clean DevTools console is not the end goal — it’s the baseline. It signals discipline, predictable behaviour, and respect for the user’s experience. The real objective is to deliver software that performs reliably, remains maintainable over time, and solves practical problems without unnecessary complexity.
Quality isn’t about ego or purism.
It’s about shipping tools that work — simply, consistently, and well.
CLARITY NOTE: The LLM’s did not return dark themed UI’s – my browser is dark themed for vision purposes.